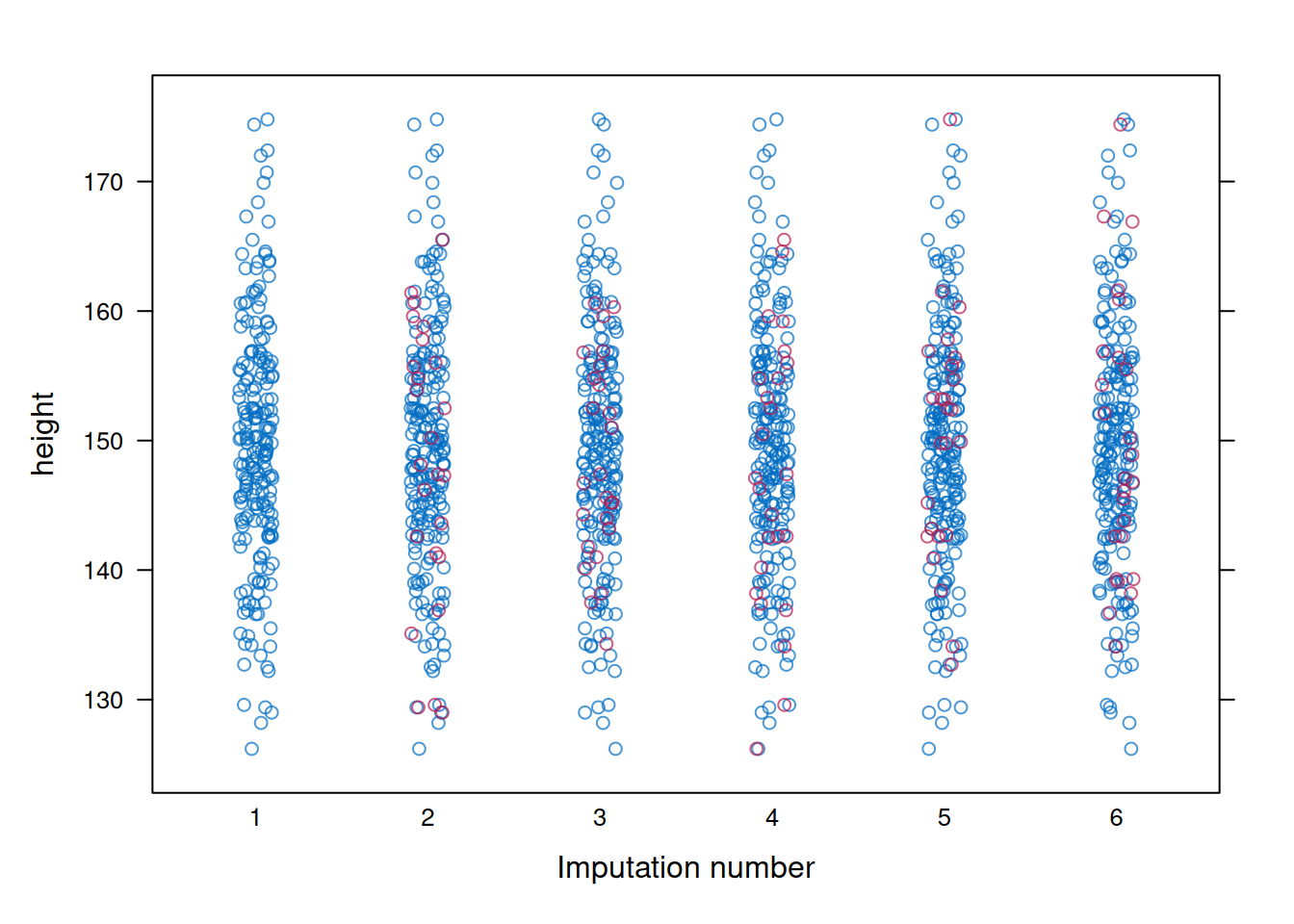
Code
#install.packages("remotes")
#remotes::install_github("DevPsyLab/petersenlab")#install.packages("remotes")
#remotes::install_github("DevPsyLab/petersenlab")data(Oxboys, package = "nlme")
Oxboys_addNA <- data.frame(Oxboys)
Oxboys_addNA <- Oxboys_addNA |>
rename(id = Subject)
Oxboys_addNA$id <- as.integer(Oxboys_addNA$id)
Oxboys_addNA$Occasion <- as.integer(Oxboys_addNA$Occasion)
set.seed(52242)
Oxboys_addNA[sample(1:nrow(Oxboys_addNA), 25), "height"] <- NA
dataToImpute <- Oxboys_addNAhttps://stefvanbuuren.name/fimd/sec-nonignorable.html (archived at https://perma.cc/N7WW-HDZF)
https://cran.r-project.org/web/packages/missingHE/vignettes/Fitting_MNAR_models_in_missingHE.html (archived at https://perma.cc/9X25-5D8G)
R packages:
jomopanAmeliaMplusR packages:
mice
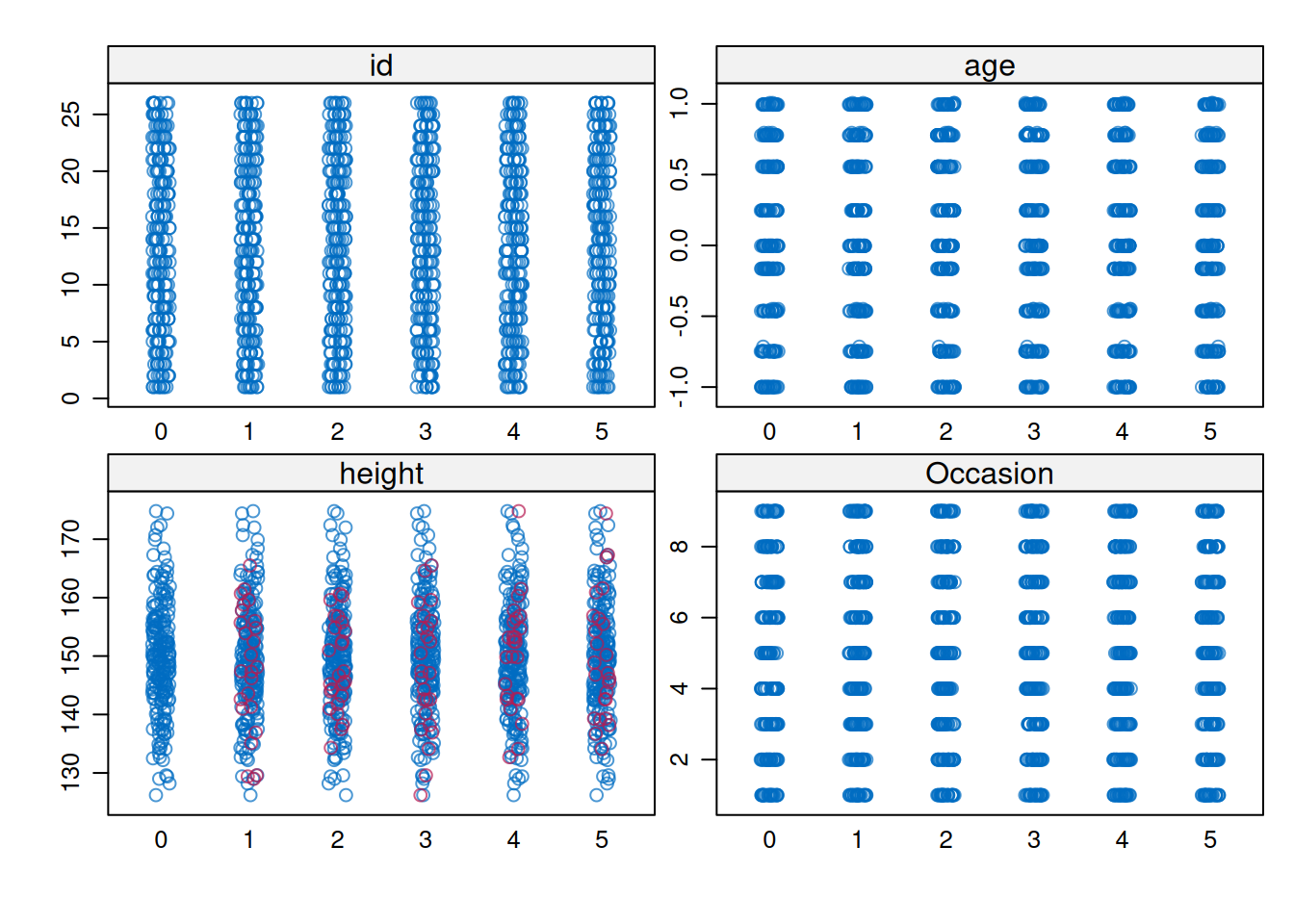
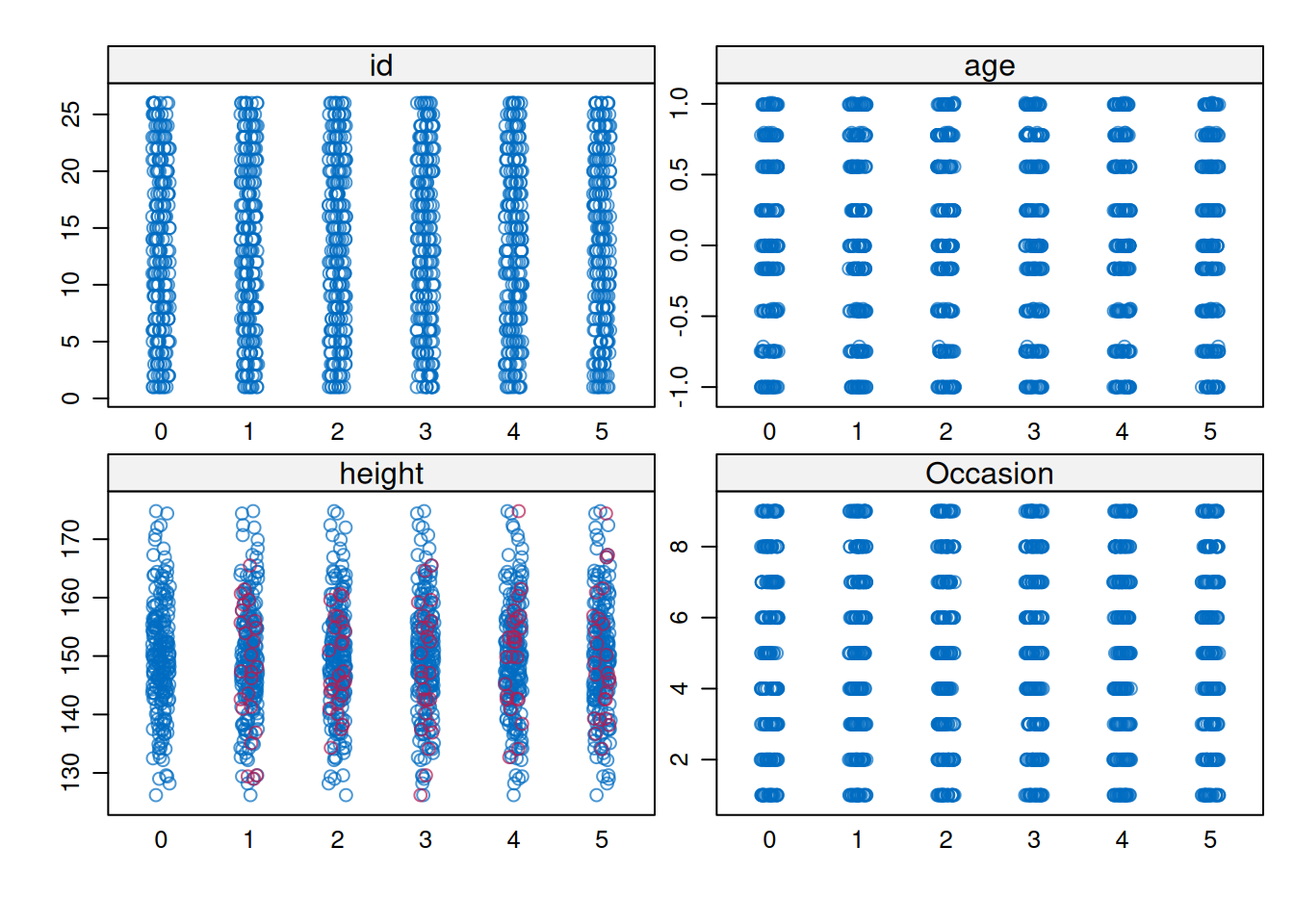
?mice::mice.impute.pmm) can be useful to obtain bounded imputations for non-normally distributed variablespsych::describe(dataToImpute)mice::md.pattern(dataToImpute, rotate.names = TRUE)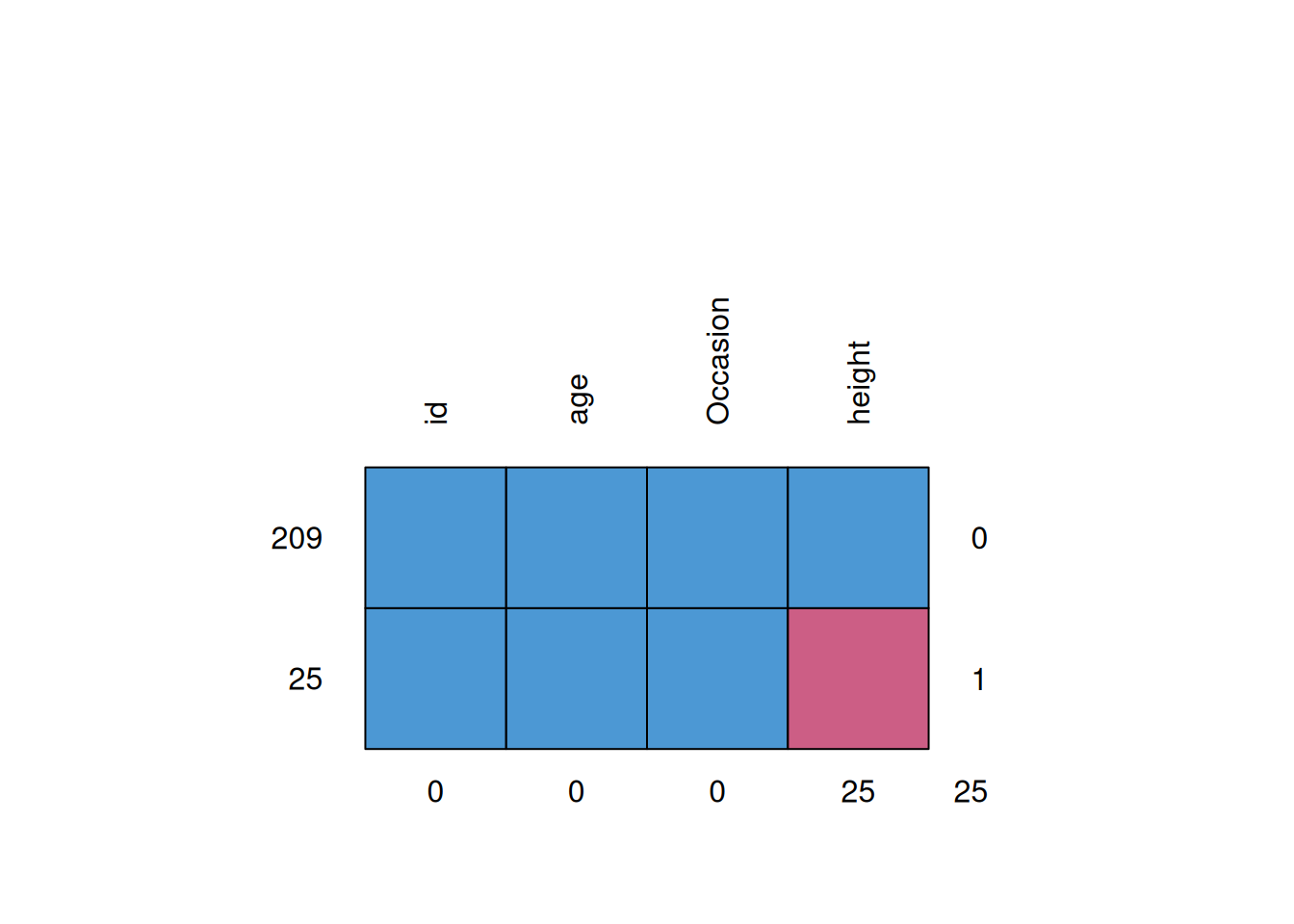
id age Occasion height
209 1 1 1 1 0
25 1 1 1 0 1
0 0 0 25 25varsToImpute <- c("height")
Y <- varsToImputenumImputations <- 5 # generally use 100 imputations; this example uses 5 for speednumCores <- parallelly::availableCores() - 1https://simongrund1.github.io/posts/multiple-imputation-for-three-level-and-cross-classified-data/ (archived at https://perma.cc/N4PP-A3V6)
mice
https://stefvanbuuren.name/fimd/sec-multioutcome.html#methods (archived at https://perma.cc/8CDA-TS3K)
?mice::mice.impute.2l.norm
?mice::mice.impute.2l.pan
?mice::mice.impute.2l.lmer
?miceadds::mice.impute.2l.pmm
?miceadds::mice.impute.2l.contextual.pmm
?miceadds::mice.impute.2l.continuous
?micemd::mice.impute.2l.2stage.norm
?micemd::mice.impute.2l.2stage.pmm
?micemd::mice.impute.2l.glm.norm
?micemd::mice.impute.2l.jomohttps://stefvanbuuren.name/fimd/sec-catoutcome.html#methods-1 (archived at https://perma.cc/5QHF-YRP6)
?mice::mice.impute.2l.bin
?miceadds::mice.impute.2l.binary
?miceadds::mice.impute.2l.pmm
?miceadds::mice.impute.2l.contextual.pmm
?micemd::mice.impute.2l.2stage.bin
?micemd::mice.impute.2l.glm.binhttps://stefvanbuuren.name/fimd/sec-multioutcome.html#methods (archived at https://perma.cc/8CDA-TS3K)
?miceadds::mice.impute.2l.pmm
?miceadds::mice.impute.2l.contextual.pmm
?micemd::mice.impute.2l.2stage.pmmhttps://stefvanbuuren.name/fimd/sec-catoutcome.html#methods-1 (archived at https://perma.cc/5QHF-YRP6)
?micemd::mice.impute.2l.2stage.pois
?micemd::mice.impute.2l.glm.pois
?countimp::mice.impute.2l.poisson
?countimp::mice.impute.2l.nb2
?countimp::mice.impute.2l.zihnbmeth <- make.method(dataToImpute)
meth[1:length(meth)] <- ""
meth[Y] <- "2l.pmm" # specify the imputation method here; this can differ by outcome variableA predictor matrix is a matrix of values, where:
The values are:
0
-2
1
2
3
4
pred <- make.predictorMatrix(dataToImpute)
pred[1:nrow(pred), 1:ncol(pred)] <- 0
pred[Y, "id"] <- (-2) # cluster variable
pred[Y, "Occasion"] <- 1 # fixed effect predictor
pred[Y, "age"] <- 2 # random effect predictor
pred[Y, Y] <- 1 # fixed effect predictor
diag(pred) <- 0
pred id age height Occasion
id 0 0 0 0
age 0 0 0 0
height -2 2 0 1
Occasion 0 0 0 0mi_mice <- mice(
as.data.frame(dataToImpute),
method = meth,
predictorMatrix = pred,
m = numImputations,
maxit = 5, # generally use 100 maximum iterations; this example uses 5 for speed
seed = 52242)
iter imp variable
1 1 height
1 2 height
1 3 height
1 4 height
1 5 height
2 1 height
2 2 height
2 3 height
2 4 height
2 5 height
3 1 height
3 2 height
3 3 height
3 4 height
3 5 height
4 1 height
4 2 height
4 3 height
4 4 height
4 5 height
5 1 height
5 2 height
5 3 height
5 4 height
5 5 heightjomo
level1Vars <- c("height")
level2Vars <- c("v3","v4")
clusterVars <- c("id")
fullyObservedCovariates <- c("age","Occasion")
set.seed(52242)
mi_jomo <- jomo(
Y = data.frame(dataToImpute[, level1Vars]),
#Y2 = data.frame(dataToImpute[, level2Vars]),
X = data.frame(dataToImpute[, fullyObservedCovariates]),
clus = data.frame(dataToImpute[, clusterVars]),
nimp = numImputations,
meth = "random"
)Amelia
! in the console output indicates that the current estimated complete data covariance matrix is not invertible* in the console output indicates that the likelihood has not monotonically increased in that stepboundVars <- c("height")
boundCols <- which(names(dataToImpute) %in% boundVars)
boundLower <- 100
boundUpper <- 200
varBounds <- cbind(boundCols, boundLower, boundUpper)
set.seed(52242)
mi_amelia <- amelia(
dataToImpute,
m = numImputations,
ts = "age",
cs = "id",
polytime = 1,
intercs = TRUE,
#ords = ordinalVars,
#bounds = varBounds,
parallel = "snow",
#ncpus = numCores,
empri = .01*nrow(dataToImpute)) # ridge prior for numerical stability-- Imputation 1 --
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
21
-- Imputation 2 --
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
-- Imputation 3 --
1 2 3 4 5 6 7 8
-- Imputation 4 --
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80
81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120
121 122 123
-- Imputation 5 --
1 2 3 4 5 6 7 8 9 10 11 12Mplus
Mplus Data FileSave R object as Mplus data file:
prepareMplusData(dataToImpute, file.path("dataToImpute.dat"))Mplus Syntax for Multilevel ImputationMplus syntax for multilevel imputation:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!! MPLUS SYNTAX LINES CANNOT EXCEED 90 CHARACTERS;
!!!!! VARIABLE NAMES AND PARAMETER LABELS CANNOT EXCEED 8 CHARACTERS EACH;
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
TITLE: Model Title
DATA: FILE = "dataToImpute.dat";
VARIABLE:
NAMES = id age height Occasion;
MISSING = .;
USEVARIABLES ARE age height Occasion;
!CATEGORICAL ARE INSERT_NAMES_OF_CATEGORICAL_VARIABLES_HERE;
CLUSTER = id;
ANALYSIS:
TYPE = twolevel basic;
bseed = 52242;
PROCESSORS = 2;
DATA IMPUTATION:
IMPUTE = age(0-100) height Occasion; !put ' (c)' after categorical vars
NDATASETS = 100;
SAVE = imp*.datPutting a range of values after a variable (e.g., 0-100) sets the lower and upper bounds of the imputed values. This would save a implist.dat file that can be used to run the model on the multiply imputed data, as shown here.
https://www.gerkovink.com/miceVignettes/futuremice/Vignette_futuremice.html (archived at https://perma.cc/4SNE-RCSR)
mi_parallel_mice <- futuremice(
dataToImpute,
method = meth,
predictorMatrix = pred,
m = numImputations,
maxit = 5, # generally use 100 maximum iterations; this example uses 5 for speed
parallelseed = 52242,
n.core = numCores,
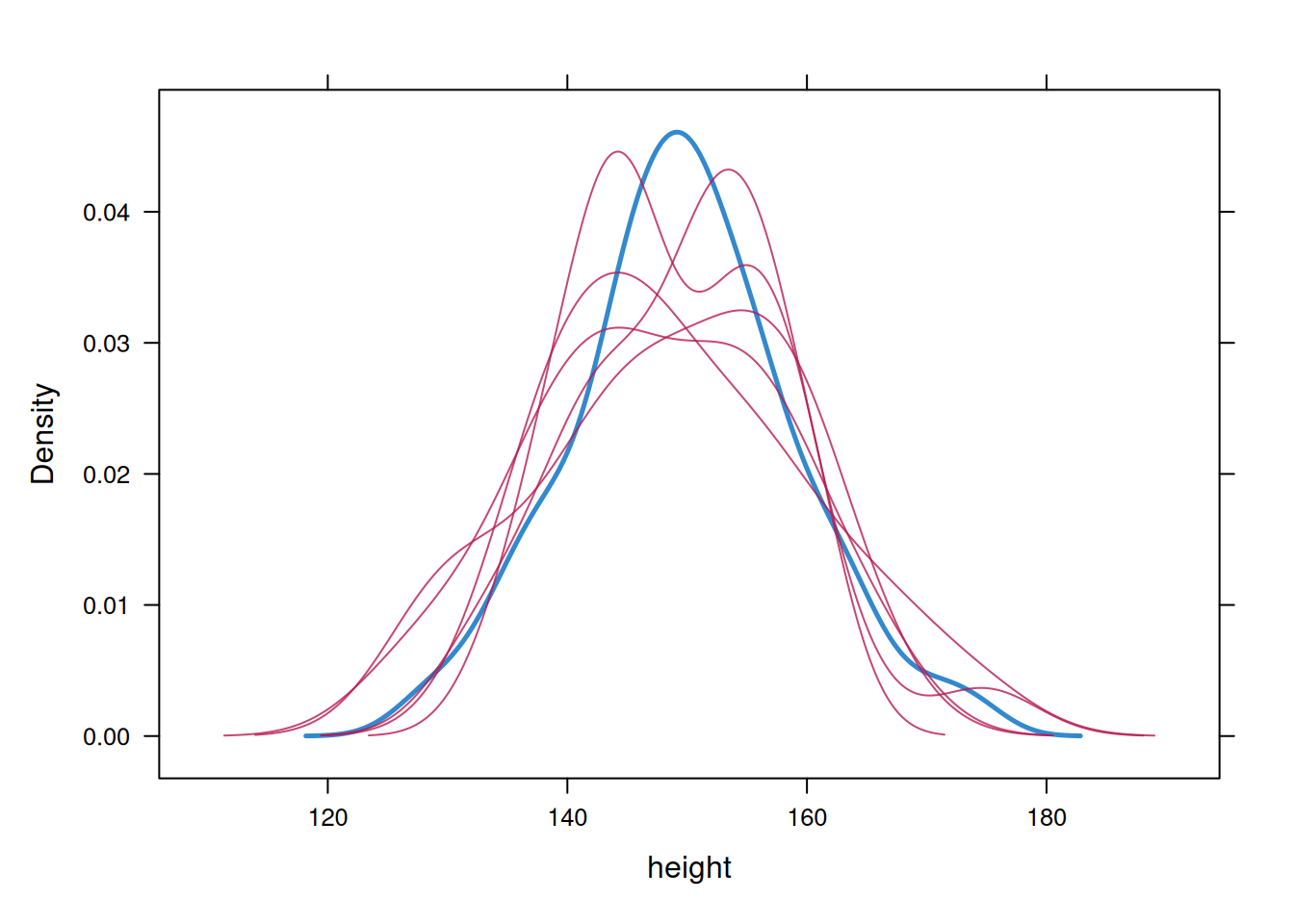
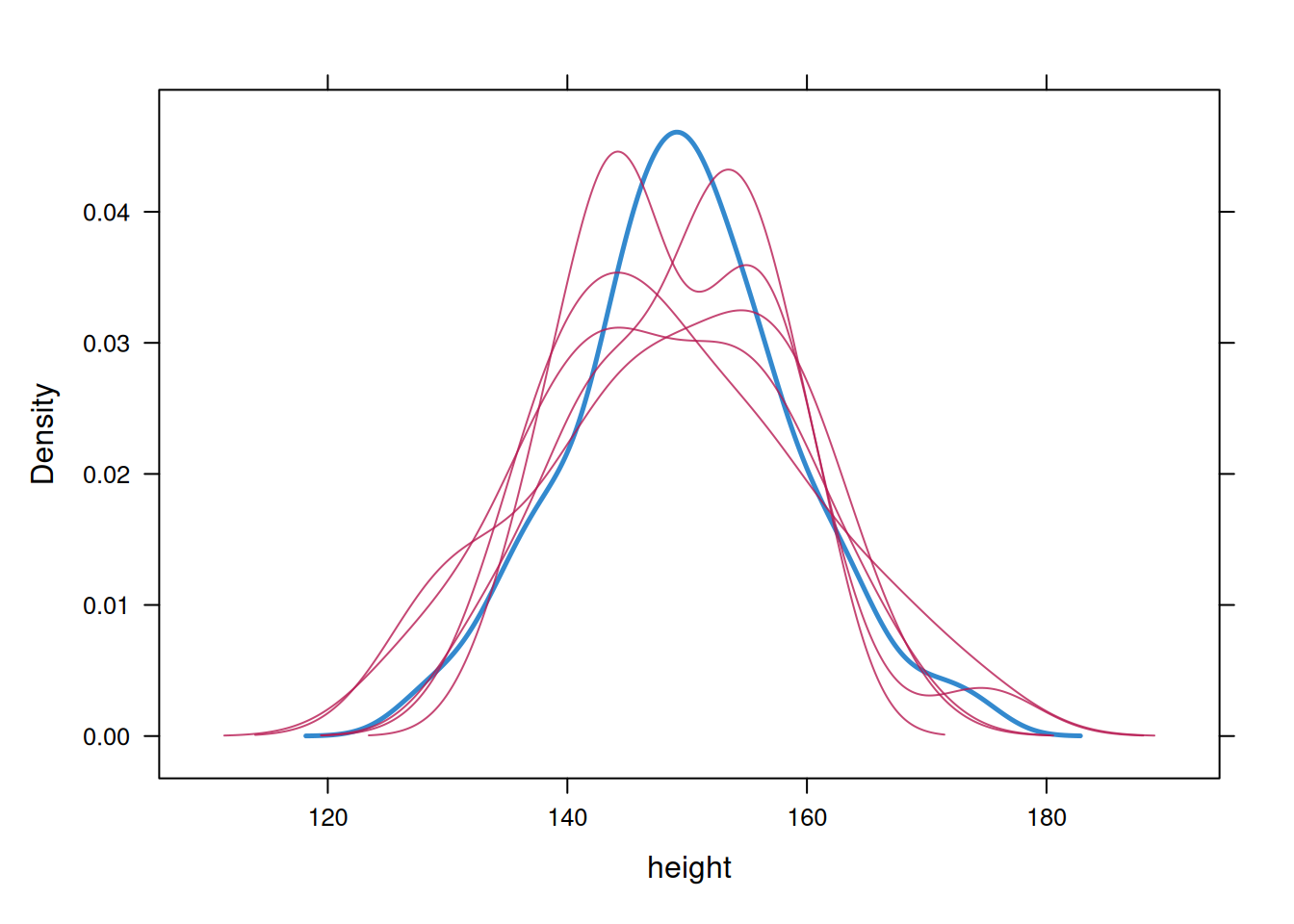
packages = "miceadds")mi_mice$loggedEventsNULLOn convergence, the streams of the trace plots should intermingle and be free of any trend (at the later iterations). Convergence is diagnosed when the variance between different sequences is no larger than the variance within each individual sequence.
mice
mi_mice_long <- complete(
mi_mice,
action = "long",
include = TRUE)
mi_mice_long$newVar <- mi_mice_long$age * mi_mice_long$heightjomo
mi_jomo <- mi_jomo |>
rename(height = dataToImpute...level1Vars.)
mi_jomo$newVar <- mi_jomo$age * mi_jomo$heightAmelia
for(i in 1:length(mi_amelia$imputations)){
mi_amelia$imputations[[i]]$newVar <- mi_amelia$imputations[[i]]$age * mi_amelia$imputations[[i]]$height
}mids objectmice
mi_mice_mids <- as.mids(mi_mice_long)jomo
mi_jomo_mids <- miceadds::jomo2mids(mi_jomo)Amelia
mi_amelia_mids <- miceadds::datlist2mids(mi_amelia$imputations)Mplus
mids2mplus(mi_mice_mids, path = file.path("InsertFilePathHere", fsep = ""))
mids2mplus(mi_jomo_mids, path = file.path("InsertFilePathHere", fsep = ""))
mids2mplus(mi_amelia_mids, path = file.path("InsertFilePathHere", fsep = ""))fit_lm_pooled <- mice::pool(fit_lm)
fit_lm_pooledClass: mipo m = 5
term m estimate ubar b t dfcom df
1 (Intercept) 5 129.438605 474.39271 16.2213875 493.85838 231 202.6802
2 age 5 -9.578321 313.63940 10.4968785 326.23565 231 203.4844
3 Occasion 5 4.074297 19.66783 0.6460228 20.44305 231 204.1678
riv lambda fmi
1 0.04103281 0.03941548 0.04875604
2 0.04016158 0.03861091 0.04792289
3 0.03941602 0.03792131 0.04720923summary(fit_lm_pooled)fit_lmer_pooled <- mice::pool(fit_lmer)
fit_lmer_pooledClass: mipo m = 5
term m estimate ubar b t dfcom df
1 (Intercept) 5 130.90722 115.993407 17.2741850 136.722429 229 91.41894
2 age 5 -8.38242 75.323709 11.3734859 88.971892 229 90.20628
3 Occasion 5 3.77516 4.723413 0.6938743 5.556062 229 92.62682
riv lambda fmi
1 0.1787086 0.1516139 0.1695846
2 0.1811937 0.1533988 0.1715650
3 0.1762813 0.1498632 0.1676435summary(fit_lmer_pooled)mice::predict_mi(
fit_lm,
#newdata = # can include if want to make predictions based on another (i.e., "new") data object
se.fit = TRUE,
interval = c("prediction")
)$fit
fit lwr upr
1 143.0912 126.6977 159.4847
2 144.7508 128.3986 161.1030
3 146.0963 129.7770 162.4156
4 147.3095 130.8591 163.7599
5 149.8360 133.5256 166.1463
6 151.5224 135.2058 167.8390
$se.fit
[1] 1.1025053 0.9291539 0.7638337 1.3045752 0.7125974 0.7486208
$df
[1] 1460.8931 1415.7428 637.8606 935.7190 6385.4620 20758.0027
$residual.scale
[1] 8.290191mice::predict_mi(
fit_lmer,
#newdata = # can include if want to make predictions based on another (i.e., "new") data object
se.fit = TRUE,
interval = c("prediction")
)Error in `predict_mi.mira()`:
! `predict_mi()` currently only works with the linear model.Error in `predict_mi.mira()`:
! `predict_mi()` currently only works with the linear model.https://stefvanbuuren.name/fimd (archived at https://perma.cc/46U2-QTM6)
https://www.gerkovink.com/miceVignettes/Multi_level/Multi_level_data.html (archived at https://perma.cc/SF32-D7ZF)
R version 4.6.1 (2026-06-24)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.4 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: UTC
tzcode source: system (glibc)
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] MplusAutomation_1.3 broom.mixed_0.2.9.7 lme4_2.0-6
[4] Matrix_1.7-5 nlme_3.1-169 furrr_0.4.0
[7] future_1.75.0 parallelly_1.48.0 jomo_2.7-6
[10] Amelia_1.8.3 Rcpp_1.1.2 mitml_0.4-5
[13] miceadds_3.20-10 micemd_1.10.1 mice_3.19.0
[16] psych_2.6.5 lubridate_1.9.5 forcats_1.0.1
[19] stringr_1.6.0 dplyr_1.2.1 purrr_1.2.2
[22] readr_2.2.0 tidyr_1.3.2 tibble_3.3.1
[25] ggplot2_4.0.3 tidyverse_2.0.0
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 jsonlite_2.0.0 GJRM_0.2-6.9
[4] shape_1.4.6.1 magrittr_2.0.5 farver_2.1.2
[7] nloptr_2.2.1 rmarkdown_2.31 vctrs_0.7.3
[10] minqa_1.2.8 htmltools_0.5.9 survey_4.5
[13] broom_1.0.13 pracma_2.4.6 htmlwidgets_1.6.4
[16] gsubfn_0.7 plyr_1.8.9 copula_1.1-7
[19] sfsmisc_1.1-24 lifecycle_1.0.5 startupmsg_1.0.0
[22] iterators_1.0.14 pkgconfig_2.0.3 R6_2.6.1
[25] fastmap_1.2.0 rbibutils_2.4.1 magic_1.6-1
[28] digest_0.6.39 numDeriv_2016.8-1.1 ismev_1.43
[31] timechange_0.4.0 pspline_1.0-21 httr_1.4.8
[34] abind_1.4-8 mgcv_1.9-4 compiler_4.6.1
[37] mvmeta_1.0.3 pander_0.6.6 withr_3.0.3
[40] gsl_2.1-9 S7_0.2.2 backports_1.5.1
[43] DBI_1.3.0 fastDummies_1.7.6 pan_2.0
[46] MASS_7.3-65 distr_2.9.7 VineCopula_2.6.1
[49] tools_4.6.1 pbivnorm_0.6.0 foreign_0.8-91
[52] trust_0.1-9 otel_0.2.0 nnet_7.3-20
[55] glue_1.8.1 stabledist_0.7-2 grid_4.6.1
[58] checkmate_2.3.4 cluster_2.1.8.2 generics_0.1.4
[61] gtable_0.3.6 tzdb_0.5.0 data.table_1.18.4
[64] hms_1.1.4 foreach_1.5.2 pillar_1.11.1
[67] mitools_2.4 splines_4.6.1 lattice_0.22-9
[70] survival_3.8-6 gmp_0.7-5.1 tidyselect_1.2.1
[73] ADGofTest_0.3 knitr_1.51 reformulas_0.4.4
[76] stats4_4.6.1 xfun_0.60 mixmeta_1.2.2
[79] texreg_1.39.5 matrixStats_1.5.0 proto_1.0.0
[82] scam_1.2-22 stringi_1.8.7 VGAM_1.1-14
[85] yaml_2.3.12 boot_1.3-32 evaluate_1.0.5
[88] codetools_0.2-20 evd_2.3-7.1 cli_3.6.6
[91] rpart_4.1.27 xtable_1.8-8 Rdpack_2.6.6
[94] distrEx_2.9.6 globals_0.19.1 coda_0.19-4.1
[97] parallel_4.6.1 listenv_1.0.0 gamlss.dist_6.1-1
[100] Rmpfr_1.1-2 glmnet_5.0 mvtnorm_1.4-2
[103] scales_1.4.0 pcaPP_2.0-5 rlang_1.3.0
[106] mnormt_2.1.2